Following yesterday's conference, I couldn't help but keep coming back to the idea of tagging. Yes, I really do mean the popular concept of tagging used on so many social web sites like del.icio.us and MySpace.
Why tagging? It's popular and it could provide a possible answer to some of the problems discussed yesterday.
Finding Projects
If projects had various tags, a user could choose to subscribe to or ignore projects based on different tags they were labelled with. These tags could used by the account managers and other sites. Then as projects appeared and disappeared they could automatically be added to your client, if you chose to do so.
User Visibility
One of the questions yesterday had to do with retaining people and them being able to see where they sat in the BOINC world. Were they advancing or falling in the listings? Did their contributions matter?
What if users tagged themselves? Say I tagged myself with: Male, USA, Single-Computer, Linux, Missouri, MoBot. Then I could see how I placed within each of those tags. I may not show up on the overall CPDN list, but I might under Single-Computer+Linux+Missouri for example.
Well, good or bad, those were some of my thoughts.
Tuesday, December 19, 2006
BOINC Conference Summary
Here is a "brief" summary of the BOINC conference that was held online, December 18th. It took place over Skype with people from all over the world. At times the connections were a little week (at least on my end), but it was a very worthwhile couple of hours.
This comes from my quickly scribbled notes. Nothing is a direct quote (unless my hand and memory got lucky) and I am sure there are many errors. I may have even missed a question or two.
If you want the definitive source, get the mp3. It should be available shortly from the BOINC UK site.
The questions mostly broke down into two basic categories. Those about BOINC in general and those specifically related to SETI@home.
General Question
If you had one wish what would it be?
BOINC Questions
With all of the optimized BOINC clients available why do we still need the "vanilla" client?
How can we resolve issues with large workunits?
Have you considered subteams or a way to give users more visibility?
What scalability issues are there as the number of projects continues to grow?
What is the status of using GPUs for computation?
Question about clients and credits.
What do you see as the relationship between BOINC and the media?
What about sandboxing?
SETI@home Questions
What is the status of the Southern Hemisphere data recorder?
What does a data recorder cost?
What it the likelihood of Arecibo shutting down?
What is the status of optical SETI work?
What percentage of stars have been listened to?
What about picking up leakage of TV, radio, and other broadcasts?
What is the projected rollout date for astropulse?
What about VLA data?
Q. With all of the optimized BOINC clients available why do we still need the "vanilla" client?
A. The optimized client was a kludge for the older version of SETI so that users would get the "correct" amount of credit. Now that SETI has moved to flops based computation there is no need for the optimized client.
Now, if you are actually talking about optimized applications (projects) as opposed to the BOINC client software that coordinates fetching workunits and running the projects on your local machine, they help. But, the issue is that there are two many distinct architectures and sub-architectures to properly test all of them.
Q. Due to the size of the Climate Prediction work units, many users simply crash and are never heard from again. How can we resolve this? Perhaps with popups and other messages? --- Mo (Maureen?)
A. We support trickle messages that can update the user as they continue to work on very large work units. Climate Prediction could do a bit of work to provide screensaver updates through using these trickle messages.
While some would like popup messages that let them know when something goes awry or needs attention, others would see this as intrusive. --- Dr. David Anderson
Q. What is the status of the Southern Hemisphere data recorder for SETI at the Parkes Observatory? --- Mark (Ohio, USA)
A. With the threatened shut down of the Arecibo telescope in 5 years we have to focus there and consider the possible transfer of equipment after that. --- Dr. Eric Korpela
Q2. What does a recorder cost? --- Mike
A2. It depends upon the donations of equipment, but even with the donations received, the original recorder cost around $300,000 (US). --- Eric
Q3. What is the likelihood of Arecibo shutting down? --- Mike
A3. The problem is that there are no congressmen with voting power for Arecibo. It is in Puerto Rico and this is really a political financial decision. --- Eric
Q. What about Optical SETI work? --- Tiare (Chile)
A. The optical work we are doing is relatively primitive compared to the radio work. It would be highly unlikely for each of our three sensors to receive a flash, although it has been guessed that a laser pulse directed at us from extraterrestrial sources could give a pulse at all three wavelengths. --- Eric
Q. If you had one wish what would it be?
A. Something indistinct about Microsoft. --- David
Better hardware --- ???
A verifiable contact --- Eric
Accurate benchmarking --- David
Q. Have you considered subgroups within teams so that users would have a better chance of seeing themselves showing up on a top 10?
A. We thought that if the servers generated sufficiently refined lists based upon data available to them that this would happen automatically. So far, it has not.
Q. What percentage of stars have been listened to? --- John (USA)
A. Arecibo has had pretty good coverage, but it only sees about 25% of the sky. Multi-beam is 30%(?) more sensitive and allows us to listen to sources that are 5 times more distant. We have also done some targeting with high bandwidth, but it is a tradeoff, bandwidth vs. coverage. We can listen to a lot on a few frequencies, or listen to a few things on a lot of frequencies.
When you look at all three, bandwidth, distances and sky coverage, we have had relatively little overall coverage. --- Eric
Q. What about picking up leakage of TV, radio, and other broadcasts?
A. Omnidirectional signals like those do not go very far. Even with a directed beam we can only reach about 50(?) lightyears with broadcasts of our own, say from Arecibo.
Q. It seems the number of projects is growing rapidly. What are the limitations of BOINC as this continues? --- Maureen
A. Since the BOINC project does not supply centralized servers,there are really no limits with respect to that. It is more a problem in terms of project discovery. BOINC account managers are one solution to that problem. BOINC mutual funds may be another.
BOINC mutual funds would be where an individual could say they are interested in computing for cancer research, but they don't want to have to keep track of cancer research projects as they come and go, so they subscribe to a "cancer research mutual fund" that would keep track of these things for them. Essentially this would be using intermediaries like the American Cancer Society to keep track of these things. --- David
Q. ATI has expressed interest in working with BOINC on producing GPU accelerated interfaces and Folding@Home has had success with a similar initiative. What is the status or progress in this area? --- Ron (Missouri, USA)
A. We tried doing some work with the NVIDIA GPUs but the architecture was not really conducive to integrating with them. It is our understanding that ATI may have a more accessible architecture, but so far no projects have bit on the offer to work with them.
We are looking at using the Cell Processor in the PlayStation® 3. It may be much better. It is several times faster than a GPU and about 50x faster than a standard processor. It also give much better computational power per Watt of electricity making it more environmentally friendly. --- David
I have not given up on GPUs. If there are any GPU programmers out there that are interesting in helping out on SETI@home, I would be very interested to hear from them. --- Eric
Q. Indistinct --- Tiare (Chile)
A. We have created a new simple GUI in cooperation with the Community Grid. It will make the BOINC client skinnable. We are also looking at a unified credit system that would allow us to grant credit for donated storage space as well as for donated CPU time. We would like to retain a single credit scoring system. But, benchmarking this is difficult. --- David
Q. What is the projected rollout date for AstroPulse? --- Derek (Guam)
AstroPulse is a long promised set of work units for SETI@home. According to a previous interview there had been a grad. student that was supposed to be working on it, but he found it more interesting to work on other things, so the effort that was put forth never came to fruition.
A. We have a new grad. student working on it. Hopefully it will be in beta next month or so. That would be nice, since he will have some time off of class then. --- Eric
Q. When the BBC did its documentary on Climate Prediction.Net it greatly enhanced the participation in the project. What do you see as the relationship between BOINC and the media? --- Maureen
A. Media coverage helps greatly. But many of those participants did not stick around long, for reasons we've already discussed. --- David
Q. Indistinct question about Sandboxing? --- Ian
A. We are using user-account based sandboxing and we recommend that the application runs as a limited user. We have this setup on the Mac already. It works with a little help on Linux as well. The problem (as usual) is Windows. Although we expect to have a Windows version of sandboxing available in about 2-3 month. --- David
Q. Something about VLA usage? --- Derek (Guam)
A. None currently. Allen(?) telescope is expanding to 45 dishes. [Garbled] needs more dishes, less than 45 does not provide what we need. Originally [garbled] was supposed to have around 200 telescopes, but due to cutbacks this has not happened. --- Eric
Well that's all I have from my notes, and a little memory thrown in.
I'd like to thank Mike and all those that arranged the conference and David and Eric for taking time out to answer our questions.
This comes from my quickly scribbled notes. Nothing is a direct quote (unless my hand and memory got lucky) and I am sure there are many errors. I may have even missed a question or two.
If you want the definitive source, get the mp3. It should be available shortly from the BOINC UK site.
The questions mostly broke down into two basic categories. Those about BOINC in general and those specifically related to SETI@home.
General Question
If you had one wish what would it be?
BOINC Questions
With all of the optimized BOINC clients available why do we still need the "vanilla" client?
How can we resolve issues with large workunits?
Have you considered subteams or a way to give users more visibility?
What scalability issues are there as the number of projects continues to grow?
What is the status of using GPUs for computation?
Question about clients and credits.
What do you see as the relationship between BOINC and the media?
What about sandboxing?
SETI@home Questions
What is the status of the Southern Hemisphere data recorder?
What does a data recorder cost?
What it the likelihood of Arecibo shutting down?
What is the status of optical SETI work?
What percentage of stars have been listened to?
What about picking up leakage of TV, radio, and other broadcasts?
What is the projected rollout date for astropulse?
What about VLA data?
Q. With all of the optimized BOINC clients available why do we still need the "vanilla" client?
A. The optimized client was a kludge for the older version of SETI so that users would get the "correct" amount of credit. Now that SETI has moved to flops based computation there is no need for the optimized client.
Now, if you are actually talking about optimized applications (projects) as opposed to the BOINC client software that coordinates fetching workunits and running the projects on your local machine, they help. But, the issue is that there are two many distinct architectures and sub-architectures to properly test all of them.
Q. Due to the size of the Climate Prediction work units, many users simply crash and are never heard from again. How can we resolve this? Perhaps with popups and other messages? --- Mo (Maureen?)
A. We support trickle messages that can update the user as they continue to work on very large work units. Climate Prediction could do a bit of work to provide screensaver updates through using these trickle messages.
While some would like popup messages that let them know when something goes awry or needs attention, others would see this as intrusive. --- Dr. David Anderson
Q. What is the status of the Southern Hemisphere data recorder for SETI at the Parkes Observatory? --- Mark (Ohio, USA)
A. With the threatened shut down of the Arecibo telescope in 5 years we have to focus there and consider the possible transfer of equipment after that. --- Dr. Eric Korpela
Q2. What does a recorder cost? --- Mike
A2. It depends upon the donations of equipment, but even with the donations received, the original recorder cost around $300,000 (US). --- Eric
Q3. What is the likelihood of Arecibo shutting down? --- Mike
A3. The problem is that there are no congressmen with voting power for Arecibo. It is in Puerto Rico and this is really a political financial decision. --- Eric
Q. What about Optical SETI work? --- Tiare (Chile)
A. The optical work we are doing is relatively primitive compared to the radio work. It would be highly unlikely for each of our three sensors to receive a flash, although it has been guessed that a laser pulse directed at us from extraterrestrial sources could give a pulse at all three wavelengths. --- Eric
Q. If you had one wish what would it be?
A. Something indistinct about Microsoft. --- David
Better hardware --- ???
A verifiable contact --- Eric
Accurate benchmarking --- David
Q. Have you considered subgroups within teams so that users would have a better chance of seeing themselves showing up on a top 10?
A. We thought that if the servers generated sufficiently refined lists based upon data available to them that this would happen automatically. So far, it has not.
Q. What percentage of stars have been listened to? --- John (USA)
A. Arecibo has had pretty good coverage, but it only sees about 25% of the sky. Multi-beam is 30%(?) more sensitive and allows us to listen to sources that are 5 times more distant. We have also done some targeting with high bandwidth, but it is a tradeoff, bandwidth vs. coverage. We can listen to a lot on a few frequencies, or listen to a few things on a lot of frequencies.
When you look at all three, bandwidth, distances and sky coverage, we have had relatively little overall coverage. --- Eric
Q. What about picking up leakage of TV, radio, and other broadcasts?
A. Omnidirectional signals like those do not go very far. Even with a directed beam we can only reach about 50(?) lightyears with broadcasts of our own, say from Arecibo.
Q. It seems the number of projects is growing rapidly. What are the limitations of BOINC as this continues? --- Maureen
A. Since the BOINC project does not supply centralized servers,there are really no limits with respect to that. It is more a problem in terms of project discovery. BOINC account managers are one solution to that problem. BOINC mutual funds may be another.
BOINC mutual funds would be where an individual could say they are interested in computing for cancer research, but they don't want to have to keep track of cancer research projects as they come and go, so they subscribe to a "cancer research mutual fund" that would keep track of these things for them. Essentially this would be using intermediaries like the American Cancer Society to keep track of these things. --- David
Q. ATI has expressed interest in working with BOINC on producing GPU accelerated interfaces and Folding@Home has had success with a similar initiative. What is the status or progress in this area? --- Ron (Missouri, USA)
A. We tried doing some work with the NVIDIA GPUs but the architecture was not really conducive to integrating with them. It is our understanding that ATI may have a more accessible architecture, but so far no projects have bit on the offer to work with them.
We are looking at using the Cell Processor in the PlayStation® 3. It may be much better. It is several times faster than a GPU and about 50x faster than a standard processor. It also give much better computational power per Watt of electricity making it more environmentally friendly. --- David
I have not given up on GPUs. If there are any GPU programmers out there that are interesting in helping out on SETI@home, I would be very interested to hear from them. --- Eric
Q. Indistinct --- Tiare (Chile)
A. We have created a new simple GUI in cooperation with the Community Grid. It will make the BOINC client skinnable. We are also looking at a unified credit system that would allow us to grant credit for donated storage space as well as for donated CPU time. We would like to retain a single credit scoring system. But, benchmarking this is difficult. --- David
Q. What is the projected rollout date for AstroPulse? --- Derek (Guam)
AstroPulse is a long promised set of work units for SETI@home. According to a previous interview there had been a grad. student that was supposed to be working on it, but he found it more interesting to work on other things, so the effort that was put forth never came to fruition.
A. We have a new grad. student working on it. Hopefully it will be in beta next month or so. That would be nice, since he will have some time off of class then. --- Eric
Q. When the BBC did its documentary on Climate Prediction.Net it greatly enhanced the participation in the project. What do you see as the relationship between BOINC and the media? --- Maureen
A. Media coverage helps greatly. But many of those participants did not stick around long, for reasons we've already discussed. --- David
Q. Indistinct question about Sandboxing? --- Ian
A. We are using user-account based sandboxing and we recommend that the application runs as a limited user. We have this setup on the Mac already. It works with a little help on Linux as well. The problem (as usual) is Windows. Although we expect to have a Windows version of sandboxing available in about 2-3 month. --- David
Q. Something about VLA usage? --- Derek (Guam)
A. None currently. Allen(?) telescope is expanding to 45 dishes. [Garbled] needs more dishes, less than 45 does not provide what we need. Originally [garbled] was supposed to have around 200 telescopes, but due to cutbacks this has not happened. --- Eric
Well that's all I have from my notes, and a little memory thrown in.
I'd like to thank Mike and all those that arranged the conference and David and Eric for taking time out to answer our questions.
Monday, December 18, 2006
Visual SourceSafe 2005 on Linux
Getting Visual SourceSafe 2005 working on Linux was a little tricky. It required a lot of experimentation, and I did not keep exact notes. So, this is just a rough outline of how I got it working.
Start by getting the latest version of
Install ies4linux. Only Internet Explorer 6 is required. I used a base directory of
Run
The Microsoft .NET Framework Version 2.0 must also be installed. However, the installation procedure does not appear to work under
So, run
Some of the target directories will exist in
Then, you have to find the files listed for installation into those directories. They will not appear under in the extraction directory with the names shown in the info file. Rather, they will appear with a name like the
Using it as an example, the short name would be
When I did this, at least one file was specified to be copied into two different directories.
Visual SourceSafe requires some fonts that are not normally installed for
Copy the
You might want to copy that command into a script file or create a launcher for it instead of having to type that command every time.
Start by getting the latest version of
wine from git. When you configure it, install any missing dependencies and reconfigure. Then, build and install it.Install ies4linux. Only Internet Explorer 6 is required. I used a base directory of
$HOME/.wine when I ran the installation script:./ies4linux --basedir $HOME/.wineThen, I moved all of the contents of
$HOME/.wine/ie6 into $HOME/.wine and deleted the ie6 subdirectory. If you plan on using the desktop icon, you will need to edit it to match the modified path.Run
winecfg and change the Windows Version setting to Windows 2000.The Microsoft .NET Framework Version 2.0 must also be installed. However, the installation procedure does not appear to work under
wine.So, run
cabextract on the download and then run it on the netfx.msi. This extracts a lot of files with really long names. Look at the file whose name contains _INF_. In my case this was FL_NETFXUSA_INF_92947_____X86.3643236F_FC70_11D3_A536_0090278A1BB8.It contains a list of files and target directories.
Some of the target directories will exist in
.wine/drive_c, others will need to be created.Then, you have to find the files listed for installation into those directories. They will not appear under in the extraction directory with the names shown in the info file. Rather, they will appear with a name like the
FL_NETFXUSA_INF_... file shown above.Using it as an example, the short name would be
netfxusa.inf. Simply copy those files into the appropriate target directory under the shorter name.When I did this, at least one file was specified to be copied into two different directories.
Visual SourceSafe requires some fonts that are not normally installed for
wine. I suspect it really needs Tahoma, I didn't try to narrow it down, I just copied my Windows\Fonts directory from my XP partition into the .wine/drive_c/windows/fonts subdirectory.Copy the
Program Files subdirectory from the VSS installation CD into the wine/drive_c directory. Then, run wine $HOME/.wine/drive_c/Program\ Files/Microsoft\ Visual\ SourceSafe/ssexp.exeIf everything goes well, Visual SourceSafe should display with some minor toolbar and menu issues. If you don't see a menu, pass your mouse over where it should be and the top-level items will appear.
You might want to copy that command into a script file or create a launcher for it instead of having to type that command every time.
Thursday, December 14, 2006
BOINC Server Shared Memory Error
When I first installed uppercase as a demo project on a BOINC server, I got the following message in my client messages window:
The first hint came from Nicolas Alvarez:
I had already configured
Message from server: Project encountered internal error: shared memoryLooking at the cgi.log on the server showed:
Can't attach shmem: -146 (feeder not running?)Running
bin/status also showed that BOINC was enabled, the daemons were running and also enabled (disabled=no).The first hint came from Nicolas Alvarez:
Maybe the shared memory block is owned by your user instead of boinc user as well. You should stop and restart server from the correct user.That was my exact problem. Then I got a more elaborate response from Eric Myers:$ ps aux | grep feederSee what user owns the feeder process.
The feeder has to be able to talk to the scheduler via shared memory. There are several ways to do this. I haveWell, that pretty well summed up the problem.chgrp apache bin/feederso that it runs as group
chmod g+s bin/feederapache, and thus can share memory with the scheduler cgi when it's started by apache.
Another way to do this (which I don't like as much, but works) is to make thefeedergroup 'boinc' and add theapacheuser to that group.
Either way, thefeeder(which always runs) needs to share permissions with the scheduler (cgi-bin/cgi- confusing name) so they can share memory.
I had already configured
apache to be a member of my boinc group and just needed to make sure that feeder was also running as the boinc group.
Thursday, December 07, 2006
Running libtool'd Binaries in GDB or DDD
When I started
But, having a rather bizarre gift for languages, I read what of it I could. It turns out that the problem happens when a program is built with
And... Oh, yeah this works for starting
The problem is not specific to the platform, but for the sake of the search engines, this was on CentOS-4, an RHEL4 clone, using gcc 3.4.6 20060404 (Red Hat 3.4.6-3).
gdb or ddd on my program I got a message that said:GNU gdb Red Hat Linux (6.3.0.0-1.132.EL4rh)After trying some different tools and things on my own, I searched Google. It gave me two hits on the entire web with my search phrase. The first was Programování pod Linuxem pro všechny (7), unfortunately that page is in Czech.
Copyright 2004 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i386-redhat-linux-gnu"..."program": not in executable format: File format not recognized
But, having a rather bizarre gift for languages, I read what of it I could. It turns out that the problem happens when a program is built with
libtool. The solution is, instead of runninggdb programrun,
libtool --mode=execute gdb programvery simple, very easy.
And... Oh, yeah this works for starting
ddd with program as well.The problem is not specific to the platform, but for the sake of the search engines, this was on CentOS-4, an RHEL4 clone, using gcc 3.4.6 20060404 (Red Hat 3.4.6-3).
Viewing JPEG2000 Images in Linux
While the installation is not automated, there is a JPEG2000 Linux Browser Plugin. It should work in any Mozilla-based browser running on 32-bit Intel. This would include at least Netscape, Mozilla, SeaMonkey, Firefox and Flock.
I went to the downloads page and picked binary release. From there I selected the npjp2_linux_glibc2.1_jasper_pthread link. This downloads a zip file. When you unpack it, it contains a
Copy
At this point, you should be able to view JP2000 files in the browser. The same site that provides the plugin has a test page. I was also able to use Firefox to view
I went to the downloads page and picked binary release. From there I selected the npjp2_linux_glibc2.1_jasper_pthread link. This downloads a zip file. When you unpack it, it contains a
LICENSE file and a npjp2.so file.Copy
npjp2.so to your ~/.mozilla/plugins directory. Close all tabs and windows in your browser, then restart it.At this point, you should be able to view JP2000 files in the browser. The same site that provides the plugin has a test page. I was also able to use Firefox to view
.JP2 files on my local drive.Friday, December 01, 2006
Correcting delete errors
When I initially created a simple BOINC test server and project, I had the permissions set incorrectly on the
Edit
When I did this the size of the
projects/PROJECT_NAME/upload directory. This resulted in a number of "delete file" errors from file_deleter. This is easily corrected.Edit
config.xml so that the file_deleter line contains the -retry_error switch, for example:file_deleter -d 3 -retry_errorThen a simple:
$ bin/stop && bin/startwill restart the file deleter and it will retry the files that previously generated errors.
When I did this the size of the
upload directory dropped in half.
Monday, November 27, 2006
Virtual Desktop Size in RHEL5 Beta 1
I had trouble getting the virtual screen size in RHEL5 Beta 1 to match my monitor's native resolution. It is an HP L1706 attached to a dc5100 SFF.
RHEL defaulted to 1600x1280 (or so) and the LCD's native resolution is 1280x1024 @ 60Hz. This resulted in the display panning around the virtual desktop when the mouse reached a screen edge. It also caused the menu and task bars to not always be available on screen, since they were at the edges of the virtual desktop.
Unfortunately the settings from System-->Administration-->Display,
I tried to use
So, I manually edited
This produced the desired effect, running the monitor at its recommended settings and setting the virtual desktop size to match it.
RHEL defaulted to 1600x1280 (or so) and the LCD's native resolution is 1280x1024 @ 60Hz. This resulted in the display panning around the virtual desktop when the mouse reached a screen edge. It also caused the menu and task bars to not always be available on screen, since they were at the edges of the virtual desktop.
Unfortunately the settings from System-->Administration-->Display,
system-config-display, did not correct this. X reverted to the larger size.I tried to use
system-config-display --set-resolution 1280 1024This sets the Virtual setting, but /var/log/Xorg.0.log told me there was no matching mode. Well, system-config-display has no command line switch for setting the mode(s).So, I manually edited
/etc/X11/xorg.conf to contain:SubSection "Display"in the
Virtual 1280 1024
Modes "1280x1024x60"
EndSubSection
Screen section.This produced the desired effect, running the monitor at its recommended settings and setting the virtual desktop size to match it.
Wednesday, November 22, 2006
Building BOINC Samples on CentOS
Why am I blogging this? Because I initially (and repeatedly) missed the "documentation" at the top of
Previously, I was editing the makefile to be more "portable". Only, those edits did not link against the static version of
But first, you need to build the BOINC client software. Then, as mentioned above, some of the examples like
Makefile.Previously, I was editing the makefile to be more "portable". Only, those edits did not link against the static version of
libstd++, which is the prefered way of linking applications that will be pushed down to the client. Doing so avoids runtime issues with missing or mismatched library versions.But first, you need to build the BOINC client software. Then, as mentioned above, some of the examples like
uppercase require a link to the static version of libstdc++.a. The makefiles for those projects contain:# Do this first:So, just do:
# ln -s `g++ -print-file-name=libstdc++.a`
# This creates a symbolic link to the C++ library,
# which is linked statically
ln -s `g++ -print-file-name=libstdc++.a`to get them going.
make
Building the BOINC Client on CentOS-4
UPDATE: Fixed directions on adding lines to
Both Red Hat Enterprise Linux 4 and its clone, CentOS-4, need some updated packages to build the BOINC client out of the box. For example, they both ship libcurl 7.12.1 and BOINC requires 7.15.5 or better. They already ship RPMs for the older version, we just need to create an RPM for the newer version.
The only instructions that should be CentOS specific are related to retrieving the source RPM files. For Red Hat, you might try:
Once retrieved:
Let's change to that directory to update and build cURL.
If you are going to locally compile and install software on a machine, I highly recommend creating an account at freshmeat.net and subscribing to get announcements for updates to that project. This includes security fixes. I would also recommend subscribing to the CentOS or RHEL announcement mailing list.
First, we have packages such as PHP that depend upon the libcurl version 3 ABI, so we need to arrange to have both the old version, and the new version installed. Start by:
Change
Add a Prefix: /usr line near the top of the file. This makes the package relocatable.
Delete all patches except #
After
Under
Then,
Once the updated cURL is in place we need the OpenGL and JPEG development libraries.
That's like a breath of fresh air in FOSS development. Too many projects make it difficult to get your patches accepted into the mainstream. It shouldn't be that way.
curl-local.spec.Both Red Hat Enterprise Linux 4 and its clone, CentOS-4, need some updated packages to build the BOINC client out of the box. For example, they both ship libcurl 7.12.1 and BOINC requires 7.15.5 or better. They already ship RPMs for the older version, we just need to create an RPM for the newer version.
The only instructions that should be CentOS specific are related to retrieving the source RPM files. For Red Hat, you might try:
$ sudo up2date --get-source On CentOS:$ wget ftp://rpmfind.net/linux/redhat/updates/enterprise/4AS/en/os/SRPMS/curl-$(yum -C list|grep curl-devel|awk '{print $2}').src.rpmwill work. This calls yum (which does not exist in RHEL4) to find out what the current version of curl-devel is. Then awk spits out only the version information and the whole thing is plopped down into the middle of the URL passed to wget, which retrieves the file.Once retrieved:
sudo rpm -Uhv curl*.src.rpmwill install the source and files necessary to build an RPM. Following that, everything should be available under
/usr/src/redhat.Let's change to that directory to update and build cURL.
cd /usr/src/redhatThe latest released version of cURL is always available from http://curl.haxx.se. They are very proactive in supporting the package, issuing updates, and fixing any security related bugs that are found.
If you are going to locally compile and install software on a machine, I highly recommend creating an account at freshmeat.net and subscribing to get announcements for updates to that project. This includes security fixes. I would also recommend subscribing to the CentOS or RHEL announcement mailing list.
First, we have packages such as PHP that depend upon the libcurl version 3 ABI, so we need to arrange to have both the old version, and the new version installed. Start by:
cd SPECSThen, either get the spec files from compat-curl-local.spec and curl-local.spec, saving them into the SPECS directory or create them afther this fashion:
sudo cp curl.spec compat-curl-local.specThen,
- Edit
compat-curl-local.spec: - Change the
Name:tocompat-curl - Append
.local.1to theRelease:line - Change the
Source:line to referencecurl-instead of%{name}. - Add
-n curl-%{version}to the end of the%setupline. - Save it.
sudo rpmbuild -ba compat-curl-local.specRunning:
sudo wget -P ../SOURCES http://curl.haxx.se/download/curl-7.16.0.tar.bz2will place the latest (as of this writing) released source into the
../SOURCES subdirectory.sudo cp curl.spec curl-local.specChange
sudo <your-favorite-editor> curl-local.spec
Version: to 7.16.0Change
Release: string to 0.rhel4.local.1Add a Prefix: /usr line near the top of the file. This makes the package relocatable.
Delete all patches except #
1 and renumber it to 0.After
%setup remove all %patch lines greater than 0.Under
%files add:%{_libdir}/pkgconfig/libcurl.pcThis will make sure that any version 7.16.0 that is released by Red Hat will replace our local one. Yet, it will also guarantee that no 7.x versions less than that will overwrite our local one.Then,
sudo rpmbuild -ba curl-local.specWhen this is done, it's time to install:
sudo rpm --force -Uhv ../RPMS/i386/compat-curl-7.*.local.1.i386.rpmWe first force the installation of our new
sudo rpm --force -Uhv ../RPMS/i386/compat-curl-devel-7.*.local.1.i386.rpm
sudo rpm -e curl curl-devel
sudo rpm -Uhv --prefix=/usr/local ../RPMS/i386/curl-7.16.0-0.rhel4.local.1.i386.rpm
sudo rpm -Uhv --prefix=/usr/local ../RPMS/i386/curl-devel-7.16.0-0.rhel4.local.1.i386.rpm
compat- RPMs, because they will conflict with the originals. (The supply the same files under a different name. The name change is necessary so that our newer version does not result in an upgrade removing the old ABI version 3 files entirely.) Once those are in place we remove (erase) the original packages to make way for the new ones. Then we load our new local versions prefixing them into the /usr/local hierarchy to avoid interfering with the old files.Once the updated cURL is in place we need the OpenGL and JPEG development libraries.
sudo up2date xorg-x11-devel freeglut-devel libjpeg-develAnother fairly large component that we need are the wxWidgets. We get these from building a spec file that is part of the RPMforge project. I could not find the corresponding binary RPM for RHEL4.
cd /usr/src/redhat/SPECSFor most,
sudo wget http://svn.rpmforge.net/svn/branches/rpms/matthias/wxGTK/wxGTK.spec
sudo wget -P ../SOURCES http://downloads.sourceforge.net/wxwindows/wxGTK-2.6.2.tar.bz2
sudo up2date gtk2-devel SDL-devel libgnomeprintui22-devel libpng-devel libtiff-devel
sudo rpmbuild -ba --define 'dist el4' wxGTK.spec
cd ../RPMS/<architecture>
sudo rpm -Uhv wxGTK-2.6.* wxGTK-gl-2.6* wxGTK-devel-2.6.*
<architecture> is going to be i386.cd ~/src/boincI have to commend the guys working on BOINC, especially Rom Walton. Prior to revision 1.20 of
./configure --enable-unicode
make
clientgui/SkinManager.cpp this would blow up compiling for UNICODE due to some character width mismatch errors. I sent in a patch and the very next day it was already in their CVS repository.That's like a breath of fresh air in FOSS development. Too many projects make it difficult to get your patches accepted into the mainstream. It shouldn't be that way.
Tuesday, November 21, 2006
Installing the BOINC Server Software
This explains the process of installing the actual BOINC server software on a machine and setting up a skeleton project.
After installing the development tools, it is a good idea to apply any available updates. Right-click on the Update Notification Icon and select Check for updates. If there are updates, apply all of them even the ones that are normally flagged to be skipped.
Development Tools
If you have previously followed the guide on installing CentOS-4 for a BOINC Server, you will need to add the development tools required to compile BOINC. This may be done by going to Applications-->System Settings-->Add/Remove Applications. Then, scroll down, check Development Tools and click Update. You may be prompted to insert a CentOS CD, insert either the CD (or DVD, if you have it) and continue on.After installing the development tools, it is a good idea to apply any available updates. Right-click on the Update Notification Icon and select Check for updates. If there are updates, apply all of them even the ones that are normally flagged to be skipped.
Accounts and Permissions
Since it is really too long for ablog post, read the rest of this document online at Google Documents and Spreadsheets.Sunday, November 19, 2006
Running a BOINC Server on SELinux
This is a shortened excerpt of one version of a much longer document. It has enough use on its own than I am posting it here separately.
In my previous post on Creating Users and Groups for a BOINC Server, I explained how to create the
After you have used
Assuming you have done as shown on The make_project script page and that you created a
You still have the details of writing your project and configuring Apache to serve it, but hopefully this post has helped with any SELinux issues you may have had.
In my previous post on Creating Users and Groups for a BOINC Server, I explained how to create the
boinc user and group. Here I explain how to grant the appropriate permissions to allow a project to operate without disabling or crippling SELinux.After you have used
make_project to create the basic files for a project, you need to change some of the permissions.Assuming you have done as shown on The make_project script page and that you created a
cplan project in the projects directory inside of your home directory as explained there, you will need to grant read permission to your home directory. You can do this with$ sudo chmod 755 ~That will allow the Apache webserver to access files hosted in your home directory. Then we need to grant the
boinc group access to the new files in the project.$ sudo chgrp -R boinc ~/projects/cplan/htmlWithout SELinux running this would be sufficient to allow access to the project. However, if you have SELinux enabled, a few more steps are necessary. If you loaded your project into one of the system web server directories instead of creating them within a user's directory, you should replace
httpd_user_content_t with httpd_sys_content_t in the following instructions.$ sudo chcon -R -h -t httpd_user_content_t ~/projects/cplan/htmlThe
$ sudo chcon -h -t httpd_user_content_t ~/projects/cplan
$ sudo chcon -h -t httpd_user_content_t ~/projects/cplan/config.xml
$ sudo chcon -R -h -t httpd_user_script_exec_t ~/projects/cplan/cgi-bin
chcon command changes the SELinux context that is assigned to an object. In this case were are changing the type of the object to indicate that it is for use by httpd, but resides in a user's directory. The first command recursively gives permission to the html directory. The second gives permission to be able to see config.xml in the directory and the third grants access to the configuration file itself. The last line indicates that scripts should be allowed to run in the cgi-bin directory.You still have the details of writing your project and configuring Apache to serve it, but hopefully this post has helped with any SELinux issues you may have had.
Creating Users and Groups for a BOINC Server
The BOINC Groups and permissions page covers most of what you need to know in order to set this up. But, I present this from the perspective of running a CentOS-4 server using graphical tools and performing these operations before the project is actually created.
Run Applications-->System Settings-->Users and Groups. Start by adding a user and group, both named "boinc". The following steps will create both at one time.
Run Applications-->System Settings-->Users and Groups. Start by adding a user and group, both named "boinc". The following steps will create both at one time.
- Click Add User.
- Enter a user name, I used "boinc".
- Enter a "Full Name", try "BOINC Server".
- Enter a password and confirm it.
- Set Login Shell to /sbin/nologin.
- Uncheck Create home directory.
- Check Create a private group for the user.
- Click OK.
- Click the Groups tab.
- Double-click the "boinc" group.
- Click the Group Users tab.
- Check the box next to "apache".
- Click OK.
Linux BOINC Server CentOS-4 Installation
This explains the process that was used to install CentOS 4 onto the workstation that is used as a BOINC server for SciLINC development. There may be subtle differences in the installation as described here and the installation as it may be seen if run again later. This may be due to differences in a pristine install and a re-install, it may also be due to the slightly modified installation procedure that was required to obtain the screen shots for this document. The most up to date version of this document is published online.
The original plan was to install Fedora Core because it is sponsored by Red Hat and ultimately its content feeds into the next official Red Hat Enterprise Linux, RHEL. The (possibly incomplete) document covering that is "Linux BOINC Server Fedora Core 6 Installation." These plans were changed for two reasons. One, the rate of change on the recently released Fedora Core 6 is too high to make it worth tracking for a test server deployment. And two, we discovered CentOS 4, the Community ENTerprise Operating System. This is a distribution that is built directly from the publicly available source RPMs for RHEL 4. The project's web site describes it this way:
Since it is really too long for a blog post, read the rest of this document online at Google Documents and Spreadsheets.
The original plan was to install Fedora Core because it is sponsored by Red Hat and ultimately its content feeds into the next official Red Hat Enterprise Linux, RHEL. The (possibly incomplete) document covering that is "Linux BOINC Server Fedora Core 6 Installation." These plans were changed for two reasons. One, the rate of change on the recently released Fedora Core 6 is too high to make it worth tracking for a test server deployment. And two, we discovered CentOS 4, the Community ENTerprise Operating System. This is a distribution that is built directly from the publicly available source RPMs for RHEL 4. The project's web site describes it this way:
CentOS is an Enterprise-class Linux Distribution derived from sources freely provided to the public by a prominent North American Enterprise Linux vendor. CentOS conforms fully with the upstream vendors [sic] redistribution policy and aims to be 100% binary compatible. (CentOS mainly changes packages to remove upstream vendor branding and artwork.) CentOS is free.In essence CentOS is a synthesis of Red Hat Enterprise Linux WS, ES and AS. The administrator is free to pick and choose from among the components offered by these various versions. In that sense it is suitable for desktop, workstation, and server usage.
Since it is really too long for a blog post, read the rest of this document online at Google Documents and Spreadsheets.
Wednesday, November 15, 2006
Linux BOINC Server Fedora Core 6 Installation
This document explains the process that was used to install Fedora Core 6, FC6, onto the workstation that is used as a BOINC server for SciLINC development. FC6 is also referred to by the code name, "Zod".
...
Fedora Core actually has two separate meanings. The first is in reference to the operating system itself. The second is a reference to the Fedora Core repository. The Core repository contains a set of relatively tightly managed and non-overlapping applications that may be used to configure a server, a knowledge worker desktop or a developer workstation.
Where Fedora Core has overlapping functionality is usually a matter of widely accepted "standard" packages that provide the same functionality. The vim and emacs editors are examples of this. Also, Fedora supports both the GNOME and KDE desktops. Each desktop may have some programs with similar purposes that are better integrated into its environment. The firefox and konqueror web browsers would fall into this category.
Since it is really too long for a blog post, read the rest of this document online at Google Documents and Spreadsheets.
...
Fedora Core actually has two separate meanings. The first is in reference to the operating system itself. The second is a reference to the Fedora Core repository. The Core repository contains a set of relatively tightly managed and non-overlapping applications that may be used to configure a server, a knowledge worker desktop or a developer workstation.
Where Fedora Core has overlapping functionality is usually a matter of widely accepted "standard" packages that provide the same functionality. The vim and emacs editors are examples of this. Also, Fedora supports both the GNOME and KDE desktops. Each desktop may have some programs with similar purposes that are better integrated into its environment. The firefox and konqueror web browsers would fall into this category.
Since it is really too long for a blog post, read the rest of this document online at Google Documents and Spreadsheets.
Tuesday, November 07, 2006
Configuring Xen Domain 0 Memory Allocation at Boot Time
According to the GRUB Configuration section of the Xen User Guide the memory allocation of the host operating system may be set in the
grub.conf file as follows:title Xen 3.0 / XenLinux 2.6"The kernel line tells GRUB where to find Xen itself and what boot parameters should be passed to it (in this case, setting the domain 0 memory allocation in kilobytes and the settings for the serial port)."
kernel /boot/xen-3.0.gz dom0_mem=262144
module /boot/vmlinuz-2.6-xen0 root=/dev/sda4 ro console=tty0
Monday, November 06, 2006
Setting up Completely Passwordless Bi-Directional SSH
If you have two machines and you want to be able to
You can also delete the id_dsa.pub files in the login directory of each machine. Do not copy the
ssh from "local" to "remote" without using a password at all, do the following, where $local is a command-prompt on the local machine and $remote is a prompt on the remote machine. Replace the words REMOTE and LOCAL with the actual network names of the machines:$local ssh-keygen -t dsaAt this point you should be able to:
$local scp ~/.ssh/id_dsa.pub REMOTE:.
$remote cat ~/id_dsa.pub >>~/.ssh/authorized_keys
$remote ssh-keygen -t dsa
$local scp REMOTE:.ssh/id_dsa.pub .
$local cat ~/id_dsa.pub >>~/.ssh/authorized_keys
$local ssh REMOTEwithout a password, you may be prompted to accept the fingerprint of the other machine. Do so. Then in the remote shell:
$remote ssh LOCALThis may also generate a fingerprint-acceptance message. Just accept it.
You can also delete the id_dsa.pub files in the login directory of each machine. Do not copy the
id_dsa (without the .pub extension) this is your private key and the connection is only as secure as that file. If someone has the file, they can impersonate you. This is also why some people recommend supplying a passphrase when running ssh-keygen and then using ssh-agent provide similar behavior, but with the need to enter your passphrase once per session.
Controlling Two Computers with One Keyboard and Mouse
The x2x program allows the keyboard and mouse on one X display to be used to control another X display. It also shares X clipboards between the displays. Basically this allows you to have two machines sitting side-by-side and use a single keyboard an mouse on them.
I choose to use ssh tunneling as the authentication mechanism between them. The first step is to setup passwordless ssh in both directions between the two machines. Then, I copied one of the quick-launch buttons on the GNOME menu bar to the menu bar by control-dragging it and edited the copy to have the following settings:
UPDATE: If this is run more than once, there will be multiple instances of ssh running on the remote machine. This can happen if the connection is lost for some reason and then reestablished. (Changing the remote machines firewall settings will do this.)
A simple workaround is to
I choose to use ssh tunneling as the authentication mechanism between them. The first step is to setup passwordless ssh in both directions between the two machines. Then, I copied one of the quick-launch buttons on the GNOME menu bar to the menu bar by control-dragging it and edited the copy to have the following settings:
- Type:
Application- Name:
x2x- Command:
ssh OTHER_MACHINE_NAME DISPLAY=:0.0 ssh -X THIS_MACHINE_NAME x2x -from :0 -east&- Comment:
Control the other display with this mouse and keyboard
-east command-line switch because my "other" machine sets to the right of "this" machine. So when I move the mouse off of the "this" screen to the east, right, it appears on the "other" screen and vice-versa.UPDATE: If this is run more than once, there will be multiple instances of ssh running on the remote machine. This can happen if the connection is lost for some reason and then reestablished. (Changing the remote machines firewall settings will do this.)
A simple workaround is to
kill or killall the ssh session(s) on the remote machine and then rerun this again. Before doing a killall ssh on remote, manually close any local ssh connections to the remote machine to avoid losing any unsaved data.
BOINC Stable Tag is Only for the Client
At last, David Anderson clarifies the "stable" tag for BOINC's CVS repository:
The "stable" tag applies only to the core client and Manager, NOT to the server software, API, PHP, etc. If you check out server software with the "stable" tag you'll get an old version, with lots of bugs. The most reliable server and API software is always the current version. Sorry we didn't make this clear before; I changed http://boinc.berkeley.edu/source_code.php to say this.
[boinc_dev] "stable" tag applies ONLY to client software (core client and Manager)
Wednesday, November 01, 2006
HP dc5100 Audio Problems in Linux
After installing Fedora Core 6 Linux on an HP dc5100 SFF (small form factor) machine with an "Intel Corporation 82801FB/FBM/FR/FW/FRW (ICH6 Family) AC'97 Audio Controller (rev 03)", I had a number of problems.
This will add some entries to the "Switches" tab, or add the tab if it did not already exist.
Next
- The system beep always went through the on-board speaker.
- Mute did not work.
- The head phone jack did not disable the sound playing on the built-in speaker.
Headphone Jack
Getting the head phone jack working was the easiest. Although finding out how to do this was not.- Open Volume Control, this is found under System|Preferences in GNOME.
- Select Edit|Preferences.
- Check the "Headphone Jack Sense" button.
- While you're there you might as well check "Line Jack Sense" button as well.
This will add some entries to the "Switches" tab, or add the tab if it did not already exist.
Next
- Check the "Headphone Jack Sense" and "Line Jack Sense" buttons on the "Switches" tab.
System Beep
It also turned out to be easy to disable the system beep.- Open the Sound Preferences applet under System|Preferences|Sound.
- Select the "System Beep" tab.
- Uncheck "Enable system beep".
- Optionally check "Visual system beep" and "Flash window titlebar" or "Flash entire screen".
The Use of BOINC Upload and Download Servers
Rom Walton has a good little post on the problems of using a single server for a BOINC project and the "proper" usage of upload and download servers to stem the tide of requestn being made on the database. Here is a sample:
I believe that the file upload and download servers are used as dams most of the time to keep the rest of the system from keeling over, for instance if the those servers were not keeping the hoards of machines at bay and everything was gated on the database then after an outage nobody would be able to use the website, or read/post in the forums.
ROMWORLD - FOLLOW-UP: The evils of 'Returning Results Immediately'
It's not too long and worth reading.Tuesday, October 31, 2006
Running BOINC uppercase Demo Standalone
Running the BOINC uppercase demo standalone requires a few things.
If a
- Create a text file called
inthat will serve as the input file forupper_case. - Create an empty file named
init_data.xml. - Set the
LD_LIBRARY_PATHenvironment variable to point to the current directory.
upper_case.C to in.$ cp upper_case.C inThen
init_data.xml may be created using touch.$ touch init_data.xmlFinally, I just set the
LD_LIBRARY_PATH variable when I run upper_case.$ LD_LIBRARY_PATH=. ./upper_caseAt this point the upper_case client should run standalone and display a graphics window. The window should display a sphere and cylinder configuration that bounces around as the application runs.
If a
logo.jpg file exists in the current directory, it will be displayed as a texture at the back of the area where the "ball" bounces. I just copied the boinc logo file over. Also, if you copy (or link) the Helvetica.txf from the BOINC distribution to the uppercase directory some statistics will be displayed as the application runs.
Monday, October 30, 2006
Compiling BOINC uppercase Sample on Linux
In order to compile
uppercase.C with gcc version 4.1.1, I had to change some function signatures to match their definitions, since C99 defines bool. Hopefully blogger doesn't mangle the patches given here. Just in case, there is a patch to correct the function signatures and another patch to fix OpenGL linking.diff --git a/uppercase/uc_graphics.C b/uppercase/uc_graphics.CAlso, I was trying to build uppercase, with graphics enabled. There are some files that uppercase needs to link with that are not in any of the BOINC libraries, so the must be built and linked with directly. I also changed the library handling to not be hard-wired to a given directory:
index 0563dfa..4f165b9 100644
--- a/uppercase/uc_graphics.C
+++ b/uppercase/uc_graphics.C
@@ -189,7 +189,7 @@ void app_graphics_reread_prefs(){
parse_project_prefs(uc_aid.project_preferences);
}
-void boinc_app_mouse_move(int x, int y, int left, int middle, int right) {
+void boinc_app_mouse_move(int x, int y, bool left, bool middle, bool right) {
if (left) {
pitch_angle += (y-mouse_y)*.1;
roll_angle += (x-mouse_x)*.1;
@@ -205,7 +205,7 @@ void boinc_app_mouse_move(int x, int y,
}
}
-void boinc_app_mouse_button(int x, int y, int which, int is_down) {
+void boinc_app_mouse_button(int x, int y, int which, bool is_down) {
if (is_down) {
mouse_down = true;
mouse_x = x;
diff --git a/uppercase/Makefile b/uppercase/Makefile
index 546b748..0d275c0 100644
--- a/uppercase/Makefile
+++ b/uppercase/Makefile
@@ -17,30 +17,31 @@ CXXFLAGS = -g -L$(BOINC_LIB_DIR) -L /usr/X11R6/lib -L.
+CFLAGS = $(CXXFLAGS)
# the following should be freeglut; use nm to check
-LIBGLUT = /usr/local/lib/libglut.a
-LIBGLU = /usr/X11R6/lib/libGLU.a
-LIBJPEG = /usr/lib/libjpeg.a
+LIBGLUT = -lglut
+LIBGLU = -lGLU
+LIBJPEG = -ljpeg
PROGS = upper_case upper_case.so
all: $(PROGS)
clean:
- rm $(PROGS)
+ rm $(PROGS) upper_case.o uc_graphics.o
# the -Wl,--export-dynamic causes the main program's symbols
# to be exported to the graphics library
upper_case: upper_case.o $(BOINC_API_DIR)/libboinc_api.a $(BOINC_API_DIR)/libboinc_graphics_lib.a $(BOINC_LIB_DIR)/libboinc.a
- g++ $(CXXFLAGS) -Wl,--export-dynamic -o upper_case upper_case.o libstdc++ -pthread -lboinc_api -lboinc -lboinc_graphics_lib -ldl
+ g++ $(CXXFLAGS) -Wl,--export-dynamic -o upper_case upper_case.o -lstdc++ -pthread -lboinc_api -lboinc -lboinc_graphics_lib -ldl
-upper_case.so: uc_graphics.o $(BOINC_LIB_DIR)/libboinc.a $(BOINC_API_DIR)/libboinc_graphics_impl.a
+upper_case.so: uc_graphics.o $(BOINC_API_DIR)/txf_util.o $(BOINC_API_DIR)/texfont.o $(BOINC_LIB_DIR)/libboinc.a $(BOINC_API_DIR)/libboinc_graphics_impl.a
g++ $(CXXFLAGS) -o upper_case.so -shared -fPIC -pthread - uc_graphics.o - libstdc++ + uc_graphics.o $(BOINC_API_DIR)/txf_util.o $(BOINC_API_DIR)/texfont.o + -lstdc++ -lboinc_graphics_impl -lboinc $(LIBGLUT) $(LIBGLU) $(LIBJPEG) -lGL -lX11 -lXmu -lm
Shared Memory Errors in Standalone BOINC Applications
Seeing an "error" message in stderr.out along the lines of the following
This occurs because the client is attempting to communicate with the BOINC manager, but is not being run under the manager. So, don't panic.
Can't set up shared mem: -1is not unusual when running a BOINC client standalone. As a matter of fact, it is not an error, it is the expected behavior.
This occurs because the client is attempting to communicate with the BOINC manager, but is not being run under the manager. So, don't panic.
Standalone BOINC Application dlopen Failure
When running a BOINC application standalone, you may see an error along the lines of
dlopen() failed: upper_case.so: cannot open shared object file: No such file or directory No graphics.This happens when the application tries to load its graphics library. The dynamic loader does not know to look in the local directory. Running the standalone application this way:
$ LD_LIBRARY_PATH=.:$(LD_LIBRARY_PATH) ./upper_casewill solve the problem, by telling the dynamic loader to look in the current directory.
Cannot Restore Segment Prot after Reloc Error
When running a BOINC application on Linux you may find the following in stderr.txt:
The most secure solution is to run a command like:
The final filename given above will vary depending upon the name of your application, but this example works for the uppercase BOINC sample.
There are other solutions, but they involve either turning off this protection system-wide or turning off SELinux entirely, which I do not recommend.
Error: cannot restore segment prot after reloc: Permission deniedITTVIS.com pointed me in the right direction on this one. It is an interaction with SELinux.
The most secure solution is to run a command like:
$ chcon -t texrel_shlib_t upper_case.soThis allows the BOINC application's graphics library to be relocated in memory, which should be safe, but I make no warrantees of any sort with respect to this. This command may need to be run again each time the graphics library is relinked.The final filename given above will vary depending upon the name of your application, but this example works for the uppercase BOINC sample.
There are other solutions, but they involve either turning off this protection system-wide or turning off SELinux entirely, which I do not recommend.
Friday, October 27, 2006
SIGSEGV Running Standalone BOINC Application
Here is part of an email I sent to the boinc-projects mailing list:
I am beginning work on a BOINC project and have built and installed BOINC stable. It seems to work fine, attaching to projects and doing work. But, when I try to compile and run a BOINC app standalone I invariably get a seg. fault in diagnostics_init. This has happened both with Eric Myer's 'hello' program and with 'uppercase'. Running uppercase produces a stderr.txt with the following contents:The response I received from Nicolas Alvarez was:SIGSEGV: segmentation violationStack trace (9 frames):...
./upper_case[0x8051224]
[0x462420]
/lib/libc.so.6(index+0x63)[0x4be0ac33]
./upper_case(_ZN7MIOFILE5fgetsEPci+0x61)[0x8053ba1]
./upper_case(diagnostics_init+0x27a)[0x805169a]
./upper_case(boinc_init_diagnostics+0x34)[0x8051934]
./upper_case(main+0x2d)[0x804cd45]
/lib/libc.so.6(__libc_start_main+0xdc)[0x4bdb4f2c]
./upper_case(__gxx_personality_v0+0xdd)[0x804cc41]
Exiting...
BasicallybufinMIOFILEisNULL, because becausediagnostics_inithas done anfopenand passed the results toMIOFILE::init_file. This setsfbut notbuf.
I'm not sure why this happens in standalone mode, but try creating anThis seemed to get me past this first problem.
empty file 'init_data.xml' and running app again.
Monday, October 23, 2006
Improving compile speeds on Linux
I rediscovered an old friend today, ccache. It is a compiler cache written by Andrew Tridgell of SAMBA fame.
It enhances (re-)compilation by maintaining a cache of previously built object files. This comes in very handy if you ever do:
After installing it on Fedora:
It enhances (re-)compilation by maintaining a cache of previously built object files. This comes in very handy if you ever do:
make clean; makeOr as I do, switch between development lines or versions of a program to perform a test and then have to do a full recompile each time.
After installing it on Fedora:
# yum install ccacheI did:
# ln -s $(which ccache) /usr/local/bin/gccso that it would automatically be invoked in place of the non-caching compiler.
# ln -s $(which ccache) /usr/local/bin/g++
# ln -s $(which ccache) /usr/local/bin/cc
Friday, October 20, 2006
Configuring BOINC for Linux from CVS
This is not very well documented. After trying many permutations of
I was able to build BOINC (client and server) from the latest development version in the BOINC CVS repository using the following command:
UPDATE: While I do not know, as yet, if UNICODE is required. I do know that clientgui will not build on Fedora Core 5 without it. This appears to be because
UPDATE: Installing the packages shown below allows a UNICODE build to be performed. The
This will leave a couple files in the
If, while running
If you are going to build a BOINC project on this machine, the libraries and header files will need to be installed:
autoconf, autoreconf, etc. I found Building BOINC on Unix, which mentions using _autosetup. This performs the proper sequence of auto... operations to allow configure to run.I was able to build BOINC (client and server) from the latest development version in the BOINC CVS repository using the following command:
$ ./_autosetup && ./configure --disable-unicode && makeThis is step one. From what I know of our requirements a UNICODE build will be necessary.
gtk2-unicode-release-2.6 is the only wxWidgets configuration that is available as reported by:$ wx-config --list
Default config is gtk2-unicode-release-2.6
Default config will be used for output
UPDATE: Installing the packages shown below allows a UNICODE build to be performed. The
mysql-server package only needs to be installed if the test/test_sanity.py script is going to be run, or if the BOINC server will be run from this machine. That applies to the chkconfig and service commands as well.# yum install mysql-devel freeglut-devel wxGTK-devel MySQL-python mysql-serverThis must be done logged in as
# /sbin/chkconfig --level 2345 mysqld on
# /sbin/service mysqld start
root, the superuser account, or using the su or sudo commands. Once these are installed BOINC may be built using:$ ./_autosetupNOTE: The blogger post editor seems to have a bug, it keeps wanting to insert "amp;" after the double-ampersands above. The only thing that should appear between each command is two ampersands.
$ ./configure
$ make
This will leave a couple files in the
sea subdirectory. The names will be like boinc_5.4.11_i686-pc-linux-gnu.sh and boinc_5.4.11_i686-pc-linux-gnu_debug.sh, although the numbers may vary. Running one of these will create a BOINC subdirectory that contains the BOINC software and gives instructions on starting it. The files in this directory may be used for testing a new version of BOINC and its libraries, without loading it over the production version that should be installed in /usr/local. The first program installs a non-debugging version, while the second installs a debugging version.If, while running
configure, messages appear indicating that GL, GLU, GLUT, MySQL or wxWidgets are not installed, but they are, loading ccache may correct the problem.If you are going to build a BOINC project on this machine, the libraries and header files will need to be installed:
# make installThis will place the necessary files under the
/usr/local hierarchy.
Thursday, October 12, 2006
BOINC for intra-organizational computing
Just a snippet from ACM Queue - A Conversation with David Anderson - The director of SETI@home discusses his work and the volunteer computing movement:
"BOINC works fine for intra-organizational computing also. CERN, for example, is experimenting with BOINC for a data-intensive application on its internal PCs."Perhaps this is something to consider. Although, I suppose the good reasons for doing so would have to be related to security issues.
Wednesday, October 11, 2006
Scrolling wide pre-formatted text
There are places on this blog, where I have had to post overly wide pre-formatted text. Normally these are code, command-line or file snippets. By default in the theme/template I am using this causes the text to run into the sidebar.
To correct this, I added the following CSS code to the blogger template just above the footer formatting information.
To correct this, I added the following CSS code to the blogger template just above the footer formatting information.
pre {
overflow: auto;
line-height: 1;
margin: 1em;
padding: 1em;
background: #cdf;
color: #330;
border: 1px solid #fff; }The idea for this came from pre-formated text with scroll bars at 100% width - HTML. It may not be perfect and well-styled, which is my fault, but it works.
Adding repositories to Fedora 5
While testing Fedora Core 5, FC5, on coLinux I added some repositories in search of TightVNC and other software. I added:
If we switch to Red Hat Enterprise Linux, RHEL, I will add Dag Wieers' RPMforge.net repository. It is one of the few that supports RHEL releases. However, he does not have support for FC5. So, I added Dries' repository, since they interoperate.
Freshrpms
To add freshrpms, download the configuration RPM:
To add the Dries repository create an
NB: There is some indication that the Extras (fedora.us) repository may need to be disabled.
If we switch to Red Hat Enterprise Linux, RHEL, I will add Dag Wieers' RPMforge.net repository. It is one of the few that supports RHEL releases. However, he does not have support for FC5. So, I added Dries' repository, since they interoperate.
Freshrpms
To add freshrpms, download the configuration RPM:
wget http://ftp.freshrpms.net/pub/freshrpms/fedora/linux/5/freshrpms-release/freshrpms-release-1.1-1.fc.noarch.rpmand install it using
rpm -Uhv freshrpms-release-1.1-1.fc.noarch.rpmDries
To add the Dries repository create an
/etc/yum.repos.d/dries.repo file that contains[dries]Then import the GPG key for the repository:
name=Extra Fedora rpms dries - $releasever - $basearch
baseurl=http://ftp.belnet.be/packages/dries.ulyssis.org/fedora/linux/$releasever/$basearch/dries/RPMS/
wget http://dries.ulyssis.org/rpm/RPM-GPG-KEY.dries.txtThe next time you access yum, it should update to include these repositories.
rpm --import RPM-GPG-KEY.dries.txt
NB: There is some indication that the Extras (fedora.us) repository may need to be disabled.
Fixing coLinux Fedora's passwd program
When I loaded the Fedora 5 image for coLinux, I got an error running
Someone had a similar need, only for their kernel, as reported in the e-mail [Yum] Re: yum install -force package. The solution was to run:
passwd to reset the password for root. It looked like I needed to reinstall cracklab-dicts.i386, but I didn't know how to force this. I could not uninstall it, that would uninstall all most all of Fedora, which I discovered the hard way.Someone had a similar need, only for their kernel, as reported in the e-mail [Yum] Re: yum install -force package. The solution was to run:
rpm -e --justdb --nodeps kernel-2.4.22-2gthen,
yum update kernelwould "do the right thing" and reinstall the package. Well, I had to do something slightly different:
rpm -e --justdb --nodeps cracklib-dicts.i386If that does not work try using:
yum install cracklib-dicts.i386
rpm -e --nodeps cracklib-dicts.i386instead. I did both and I'm not sure which actually permitted
yum to do its thing.
Tuesday, October 10, 2006
Dvorak on Fedora Core Linux
Typing
$ loadkeys dvorakis enough to load the dvorak keyboard layout on Fedora. But, to load it at boot time, edit the
/etc/sysconfig/keyboard file and change the KEYTABLE=... line to KEYTABLE="dvorak".
Monday, October 09, 2006
Building BOINC Applications on Windows
Eric Myers has an an excellent walk-through of setting up, configuring and Building BOINC applications on Windows.
JPEG Library
Eric's solution and project files should be automatically converted to Visual Studio 2005 format upon loading.
If you want to build a release version of the JPEG library, you will need to change a couple of the project's properties:

First, turn off the precompiled headers for the Release configuration.
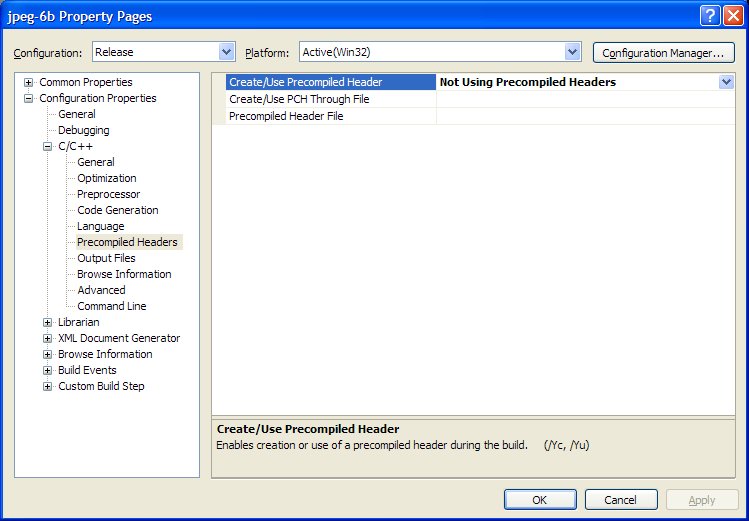
Then change the Configuration Type to Static Library (.lib).
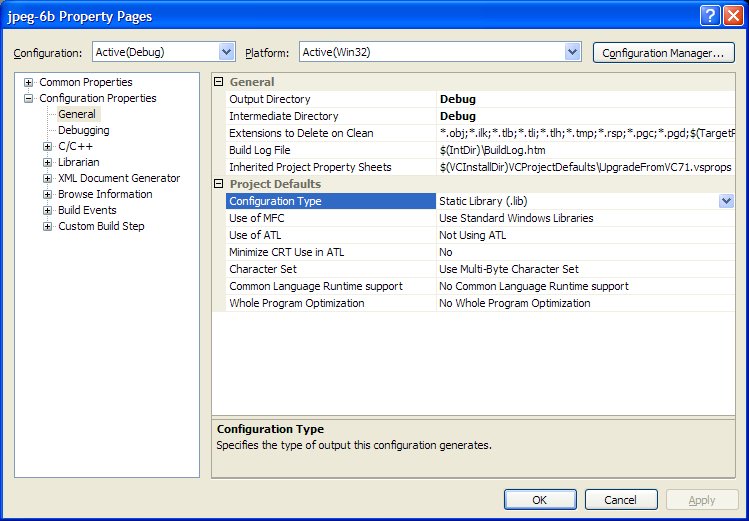
After building the JPEG library Eric suggests copying the headers and library file somewhere. So far I have not done that. I am trying to set up a single Visual Studio Solution file for BOINC development that uses dependencies and relative paths for everything.
OpenGL and GLUT
Following Eric's directions, I got the freeglut-2.4.0 distribution and decompressed it in a directory alongside my jpeg-6b directory. Then I opened the Visual Studio 6 workspace that comes with the distribution and allowed Visual Studio 2005 to automatically upgrade it. Once the Workspace has been opened as a new Solution it is set freeglut_static to be the StartUp Project (love those StudlyCaps):
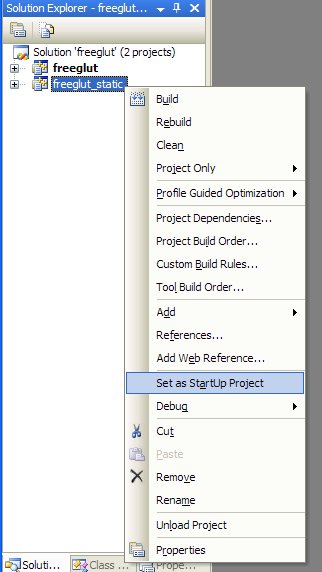
Other than selecting the static library, freeglut seems to build out of the box.
wxWidgets
The wxWidgets library is not used for BOINC application development. It is only needed to build the BOINC Manager, which can be downloaded in binary form.
Making a Large Sparse coLinux Disk Image
The directions given for ExpandingRoot - coLinux are pretty good. Instead of fsutil I used:
dd if=/dev/zero of=colinux_new bs=1 seek=10737418240 count=0in Cygwin to create a spase
cygwin_new file. Then I started coLinux, logged in as root and zero'd out most of the freespace in cygwin_old so that mkSparse could reduce the size of cygwin_newlater:
# e2fsck /dev/cobd4This zero'd out most of the free space in
# df
# dd if=/dev/zero of=/tmp/fill count=...
# rm /tmp/fill
cygwin_old. Then I did what ExpandingRoot - coLinux said to do:# dd if=/dev/cobd4 of=/dev/cobd5After downloading
# resize2fs -p /dev/cobd5
# e2fsck /dev/cobd5
# shutdown now -h
mkSparse from the coLinux file-utils described on the NiceTools page of the coLinux Wiki, I ran:C:\coLinux> mkSparse colinux_newThis turns
colinux_new into a sparse file that takes up much less room on the drive. After this is done I finished up by continuing at step 7 on the ExpandingRoot page.
Thursday, October 05, 2006
Spy Hill Research BOINC Developers' Notes
Spy Hill Research has a excellent set of BOINC Developers' Notes. They are written by Eric Myer, who was part of the Einstein@Home development team. His notes should help get a developer rapidly up to speed on developing for BOINC.
There are instructions for:
- Building BOINC applications on Windows
- Building BOINC and BOINC Applications on Linux
- Building BOINC and BOINC applications on MacOS X
Much of the notes is in the form of examples to be worked through:
- Hello, World -- the simplest BOINC program
- concat - concatenates two or more input files into one output file (from BOINC)
- Yello, World -- the simplest graphics program for BOINC,
- cube - simplest non-trivial 3D graphics application for BOINC
- uppercase - convert an input file to uppercase (from BOINC) - now with graphics
- The Jack LaLanne program - an API Exerciser
- The 'scroll' application for Pirates@Home
- The "Sicilian Roulette" application for BOINC
- Sextant - the Einstein@Home screensaver graphics thread
- Starboard! - xscreensaver GL graphics suite
These, sort of, form a self-guided tutorial. There are also links related to BOINC Graphics, Project Management, and external developer links.
BOINC Server Planning
The MyISAM engine requires the least amount of computer resources can be used where there is a low DB activity requirement. For example with query rates lower that 5/sec this table type may be adequate. Also if one does not have a dedicated DB server this may be a good choice for all the tables since it consumes much less computer resources. It has the advantages of allowing long text indices against tables which Innodb does not allow.While the page quoted above is called Configuring MySQL for BOINC, the title should have something about server capacity planning. There is much information on the physical requirements of the server hardware given the loads placed upon it by SETI@home. These loads are also documented. So the planner should be able to extrapolate something about the hardware that should be needed. The SETI@home Server Status page also lists the various servers used, as well as, their software and hardware configurations....
Innodb tables/indices are usually stored in large OS physical files and the tables and indices are managed internally within these OS/Innodb files. It is important that these files are located on high performance devices. The transaction log files should be located on independent high performance media (away from the Innodb files) for sustained high transaction rates. At DB shutdown all modified buffers have to be flushed into the transaction logs before MySQL goes away, so slow performance drives for the transaction log could delay shutdown for over 30 minutes when there are a large number of .modified buffers. to be flushed.
In contrast to SETI@home, Einstein@Home uses a single server, of unknown configuration. There is an Einstein@Home Server Status page as well. The EAH status page also makes reference to four download mirror sites. This may account for the project being able to use a single server, if the data driving the project is distributed across five different sites (including the main site).
BOINC server bottlenecks
MySQL can be the bottleneck in a BOINC server. To optimize its performance, read about configuring MySQL for BOINC.
Pertinent BOINC Server Software Prerequisities
Some parts of the BOINC server (the feeder and scheduling server) use shared memory. On hosts where these run, the operating system must have shared memory enabled, with a maximum segment size of at least 32 MB. How to do this depends on the operating system; some information is [given in the PostgreSQL documentation under Managing Kernel Resources].
This is according to the BOINC Software prerequisites page. Basically it entails setting the SHMMAX parameter.
If the server is going to be run on Windows using Cygwin then the Setting SHMMAX in Cygwin mailing list conversation is pertinent. At this point in time it has not been determined whether the server will be run on Windows (with or without Cygwin), Linux, UNIX or some other platform.
Anyone responsible for maintaining or managing a BOINC server should read the Software prerequisites page. It contains information on setting up the server, backup procedures and other important tasks.
Tuesday, October 03, 2006
BOINC Suitability
As a rule of thumb, if your application produces or consumes more than a gigabyte of data per day of CPU time, then it may be cheaper to use in-house cluster computing rather than volunteer computing.
BOINC
SciLINC will use the BOINC framework to distribute the work to volunteer's machines. A very good resource describing BOINC can be found on the Papers related to BOINC web page. Especially:
BOINC: A System for Public-Resource Computing and Storage. David P. Anderson.5th IEEE/ACM International Workshop on Grid Computing, November 8, 2004, Pittsburgh, USA.BOINC implements Public-Resource Computing. This differs from Grid-Computing in terms of security and available network bandwidth. To make efficient use of PRC the compute time of the client must be relatively large compared to the data-transfer time required.
A research scientist can create and operate a large PRC project with about a week of initial time investment and approximately an hour per week of maintenance.
"On a particular computer, the CPU might work for one project while the network is transferring files for another."
It seems to me that this is where a large bandwidth/computation project might still succeed. If the CPU is working for a computationally intensive project and the network pipe is transfering data for the data-intensive application. This would work best given a large D/L to U/L ratio, given that most consumer internet providers offer a much large pipe downstream than upstream.
(The typical server platform is LAMP with Python.)
SciLINC - Scientific Literature Indexing on Networked Computers
This blog is all about the development of SciLINC - Scientific Literature Indexing on Networked Computers the Missouri Botanical Garden's public-resource computing application that will automatically index large amounts of digitized scientific literature.
You will find information on development progress, background information on the project and developer notes. Much of what is here will simply be a collection of information that I want to be able to refer back to as development progresses.
Subscribe to:
Posts (Atom)